what is a directory-based sharding?
Directory-based sharding basically allows the user to define the values used and combined across different partitions, providing better control over data location, in which partition, and which shard. So this allows you to set up a good configuration.
Now, many times we may have a key that isn’t large enough for hash partitioning to distribute the data evenly. Sometimes we may not even know which keys will come in the future. And these need to be built in the future. So, when building these, you really don’t want to have to reorganize the whole database on new hash functions, and when data cannot be managed and distributed using hash partitioning, or when we need full control over where data exists.
So let’s say our company is very small in three different countries. So I can combine those three countries into one single shard. And then have three other big countries, each sitting in its own shard. So all of this is done through this directory-based sharding. However, what is good about this is that the directory, which is a table, is created behind the scenes, stored in the catalog, available to the client, and cached with them, used for connection mapping, and used for data access. So it can offer you many high-level benefits.
So the first benefit allows you to group the data based on whatever values you want, depending on where you want to put them, across shards. So all of that is much better and easier controlled by us or by the designers. Now, this is when there are not enough values available. So when you use a hash-based partition, you get an uneven distribution of data.
Therefore, we may be able to use this directory to better distribute the data, since we understand the data structure better than just the hash function. And having a specification that lets you create future components and partitions, depending on how large they’re going to be. Maybe you’re creating them with an existing shard and later moving them to another shard. The ability to have all those controls is essential for managing this specific type of data.
And finally, if a shard value, the key value is required, for example, as we said, the client getting too big or can use the key value, split it, or get multiple key values. Combine them. Move data from one location to another. So all of these components are automatically maintained behind the scenes by us, with the changes applied. And then the directory sharding, and the sharded database, manage all of the data structure, movement, and everything behind the scenes using some of the future functionalities, as we will also talk about.
And finally, a large chunk of data that can then be moved from one location to another. As I mentioned, this is part of the automatic chunk data move and whatnot that we will see later, but utilized within the directory-based sharding to allow us the control of this data and how we’re going to move and manage the data based on the load, as the load or the size of the data changes.
Generally, two types of use case bases, as we talked about. One, as we said, is when there are not enough distinct values available for the hash distribution to be evenly across the shard. Or if we need to have control over how the data is actually distributed, what data partitions are put together, the chunks? And these chunks, where are they located?
Now, what goes on under the hood? Basically, you identify your mapping key values based on the sharding, where they’re going to be placed. And all of these are then stored in the directory table, as we’ll see in just a minute.
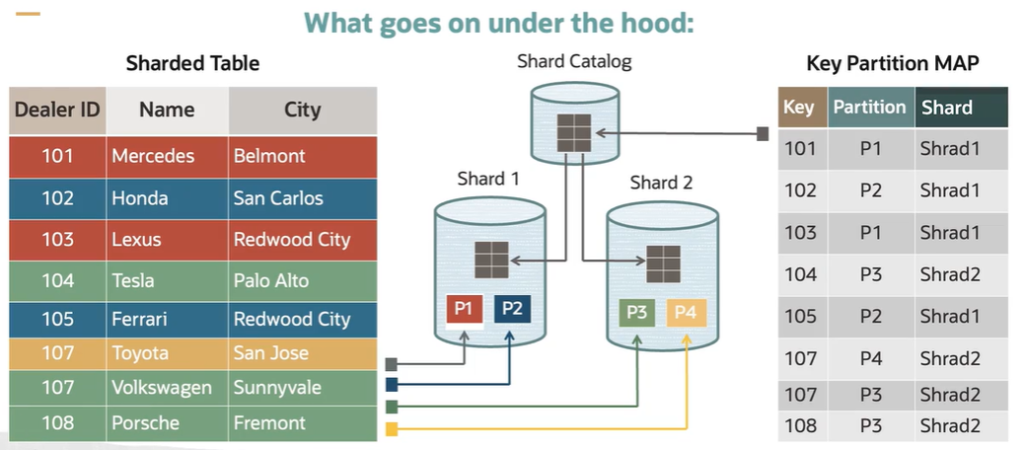
The directory table is then automatically created and stored in the shard catalog. And it is also shared by the director and the client, so it is used for better routing of connections and requests, as well as better data selection. So on the client side, the connection pool, then you create them based on the directory information that is cached. So all of these routing operations can then be performed more efficiently based on the structure.
And then, as I mentioned, this directory is automatically maintained by Oracle. As you insert, delete, alter, or make changes to the data, these operations are automatically maintained for data management. Now, the sharded table contains a virtual column that provides this type of partitioning information, which is used behind the scenes to improve pruning and data management for client access.
So here, if we take a look under the hood of what we have available and what goes on, you can see that we create a shard table. In the shard table, we identify the key that determines how the data is distributed. Then the rest of the information about the data, that is provided in the sharded table.
Then, based on our structure and the mapping we have defined, we will assign each specific partition to a particular shard. So here, these partitions are mapped to this particular shard. And then the other partitions are mapped to this shard.
So behind the scene, the mapping table that we talked about, the directory is created, where it identifies the rows, identifies which partition they belong to and which shard those partitions are stored at. So this can then be cached both, as we said, on the client and in the database for routing, for better execution and load management.
Now, how do we use it? Basically, when we create a sharded table, we specify that we will partition by directory. Then we identify the key column or the key column list if there is more than one. And then, of course, we build our partitions and then identify exactly what the different conditions are for each partition, where each one is going. And then based on the structure, the table is built and then maintained behind the scenes.

In the future, remember, we said that sometimes we don’t know specific new partitions or something that is coming in. You can go ahead and alter a table and add a partition, identify the tablespace and places where that information is going to go to. Next, you can split an existing partition. So here, we are doing the ALTER TABLE SPLIT PARTITION. And then we identify how to divide that particular partition into multiple partitions. So then the structures would be properly created and maintained behind the scenes.

So this gives you an overview of directory-based sharding. I hope it helps.


Recent Comments