If you’ve been in software development for a while, you’ve probably heard the term “microservices” thrown around a lot. Let me break it down for you in a way that actually makes sense.
At its core, microservices is an approach to building software in which you decompose your application into small, individual components — each handling a specific piece of functionality, deployable on its own, and communicating with the others through APIs. That’s the big idea.
What makes this powerful is that microservices lean heavily on integration, API management, and cloud deployment technologies. This gives developers the freedom to build and ship individual services without waiting on the rest of the team or the rest of the application.
The Key Characteristics You Need to Know
Multilingual by design. One of my favorite things about microservices is that your teams aren’t locked into a single technology. One developer can write a feature in Node.js, another in Python — and the overall architecture doesn’t care. Each service speaks its own language, as long as it communicates properly with the rest.
Loosely coupled. In a microservices environment, services are intentionally isolated from each other. This is a big deal because when something slows down or breaks, you can target that specific component without touching everything else. Loose coupling directly translates to better productivity and fewer headaches.
Easy to maintain and deploy independently. Because each service is isolated, the codebase for any given service stays small and focused. Need to make a change? You update and redeploy just that one service — not the entire application. This alone is a game-changer for teams that ship frequently.
Scalable and highly available. Microservices are built to scale. You can scale individual services based on demand without dragging the whole application down. Using techniques such as load balancing and API gateways, you can maintain high availability without excessive operational complexity.
Failure-resistant. Here’s where microservices really shine. You can build fault tolerance directly into your services so that when one goes down, the rest of the application doesn’t go down with it. Think about a movie ticket app — if the customer preferences service fails, you’d still want scheduling and purchasing to keep working. With microservices and proper fault tolerance policies, that’s entirely achievable.
What Does a Microservices Architecture Actually Look Like?
Let me walk you through a sample e-commerce application to make this concrete.
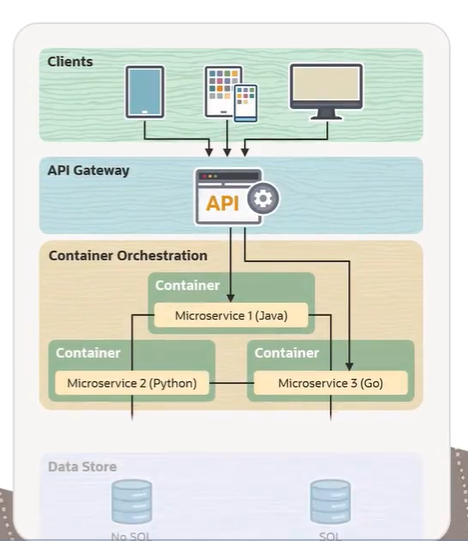
The architecture is typically organized into three layers. First, there’s the API layer — this is the entry point for all client requests. It’s also what allows microservices to communicate using protocols such as HTTP and gRPC.
Then comes the logic layer, where the actual business logic lives. Each microservice focuses on a single task and keeps its dependencies on other services to a minimum. In our e-commerce example, you might have three microservices — one written in Java, one in Python, one in Go. That multilingual setup is completely normal and intentional.
Finally, there’s the data store layer. This is where persistence happens — databases, log files, and so on. Importantly, each microservice can have its own dedicated data store, reinforcing the independence we discussed earlier.
Each of these microservices typically runs in a container, providing a lightweight, isolated runtime environment. And when traffic spikes or a service needs more resources, orchestration tools like Kubernetes handle the scaling.
Microservices vs. Monolithic Architecture: The Real Difference
To really appreciate microservices, you need to understand what came before — and what a lot of teams are still dealing with today: the monolithic architecture.
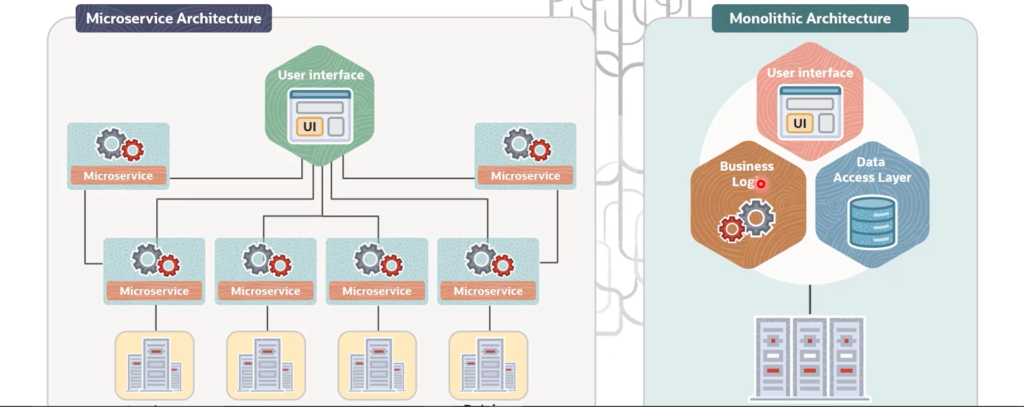
In a monolith, the entire application — business logic, user interface, data access — is built and deployed as one single unit. Everything shares the same resources and the same database, which means everything is tightly dependent on everything else. The fatal flaw? If one part of that application breaks, the whole thing can go down.
Microservices flip this on its head. The business logic is split across multiple loosely coupled services, each with its own resources, each running independently. If one service crashes, the others keep running.
Here’s a quick side-by-side of how these two approaches differ across several dimensions:
- Unit design: Microservices are loosely coupled, independently deployable units. Monoliths are designed, built, and shipped as a single unit.
- Functionality reuse: Microservices expose APIs that any client can consume. Monoliths have very limited reuse.
- Communication: Microservices use RESTful HTTP API calls. Monoliths use internal function calls.
- Tech flexibility: With microservices, you pick the best language or framework for each job. With a monolith, you’re locked into one language across the board.
- Data management: Microservices allow decentralized, per-service data stores. Monoliths require a single centralized database.
- Deployment: Each microservice deploys independently. A monolith requires the entire codebase to be redeployed every time — even for a minor change.
- Maintainability: Smaller codebases are easier to manage. A monolith grows into a complex beast over time.
- Resilience: Microservices are highly resilient. Monoliths, not so much.
- Scalability: You can scale individual microservices on demand. With a monolith, you scale the entire thing whether you need to or not.
How Microservices Actually Talk to Each Other
Since microservices are distributed by nature, they can’t just call each other as functions in the same codebase do. They communicate over the network, using inter-service communication protocols. And understanding how to design that communication is honestly one of the most important parts of getting microservices right.
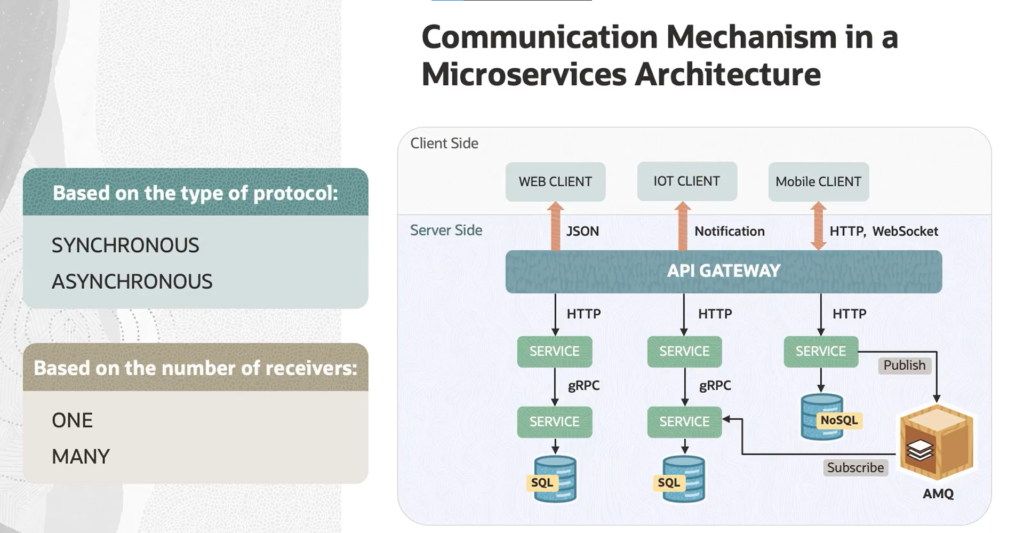
There are two ways to think about this: the protocol type (synchronous or asynchronous) and the number of receivers (one or many).
Synchronous communication uses protocols such as HTTP, HTTPS, and gRPC. The client sends a request and blocks — it waits for a response. Simple, predictable, but it does mean your client is tied up during that wait.
Asynchronous communication works differently. Here, the client sends a message and moves on — it doesn’t sit around waiting for a response. The most popular protocol for this is AMQP (Advanced Message Queuing Protocol), and the most common tools implementing it are Kafka and RabbitMQ. The client sends its message to a broker, which handles delivery.
One thing worth keeping in mind: inter-service communication means a lot of network traffic. That makes serialization speed and payload size genuinely important concerns. For internal communication within your microservices cluster, binary protocols like gRPC are often the better choice than plain HTTP — they’re faster and more efficient.
The second dimension — the number of receivers — yields two more patterns. Single-receiver communication means one request goes to one service (think: command pattern). Multiple-receiver communication is the foundation of event-driven microservice architectures, where an event bus broadcasts updates across services, and any service that cares about that event can react to it.
In practice, most real-world microservices applications combine several of these styles. The most common setup? Single-receiver communication over HTTP or HTTPS for straightforward request-response flows, layered with asynchronous messaging where you need decoupling and resilience.
That’s the full picture of microservices — what they are, how they’re structured, how they compare to monoliths, and how they communicate. Once you internalize these concepts, you’ll start seeing both the power and the complexity of this architecture much more clearly.


Recent Comments