let’s start by talking about what is database sharding and what is an Oracle Database Sharding.
So the sharding of the database, this is basically an architecture to allow you to divide data for better computing and scaling across multiple environments instead of having a single system performing the work. So this allows you to do hyperscale computing and other different technologies that are included that will allow you to distribute your queries and all other requests across these multiple components to be able to get a very fast response.
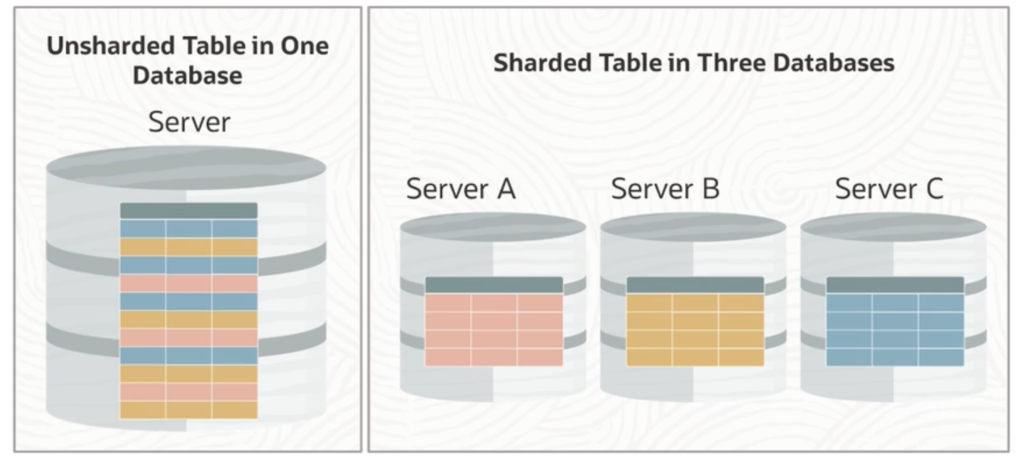
Now many times with this distributed segment across each kind of database that is called a shard allow you to have some geographical location component while you are not really sharing any of the servers or the components. So it allows you separation and data management for each of the shards separately. However, when it comes to the application, the sharded database is totally invisible. So as far as the application is concerned, they connect to a global service, submit their statements. Everything else is managed then by the sharded database underneath.
Now with sharded tables, basically it gets distributed across each shard. Normally, this is done through horizontal partitioning. And then the data depending on the partitioning scheme will be distributed across like server A, server B, server C, which are independent servers that are running independent databases.
Now the Oracle Database Sharding allows you to automate how the data is distributed, replicated, and maintain the kind of a directory that defines the complete sharding scheme, while everything is distributed across many servers with no sharing whether the hardware or software. It allows you to have a very good scaling to be able to scale based on this partitioning across all of these independent servers.
And based on the subset and the discrete data configuration, you can go ahead and distribute this data across these components where each shard is an independent data location or data component, a subset of data that can be used, whether individually on its own or globally across all of the shards together. And as we said to the application, the Oracle Database Sharding also looks as a single component.
So with Oracle Database, you basically have linear scaling capability across as many shards as you like. And all of the different database configurations are supported with this. So you can have rack databases across the shards, Oracle Data Guard, GoldenGate. So all of the different components are still used to give you all of the high availability and every other kind of functionality that we generally used to having a single database with. It provides you with fault toleration.
So each component could be down. It could have its own replicated data. It doesn’t affect other location and availability of the data in those other locations. And finally, depending on data sovereignty and configuration, you could actually distribute data geographically across the different locations based on requirements and also data access to provide a higher speed for local data management.
So some of the use case basis is having to have a very high OLTP environment. So with this OLTP environment, some other databases that has been used could have been Cassandra the MongoDB, the MariaDB. But with Oracle database, of course, you get all of this better administration of the transactional operation and data administration.
You could have global databases, depending on data sovereignty, data locations, as we talked about, managing logs and text operations, dealing with metric time data that is partitioned based on locational aspect, and then could be sub-partitioned based on time basis, and data that is used for machine learning and also the big data for data analytics. And as you can see, there have been other databases that has been used to provide similar options, what Oracle can provide for the clients.


Recent Comments